

メルマガ登録
ベストなDXへの入り口が見つかるメディア


-
テーマから探す
-
技術から探す
-
業界・事例から探す
-
関連トレンドから探す
ベストなDXへの入り口が見つかるメディア
テーマから探す
技術から探す
業界・事例から探す
関連トレンドから探す

最終更新日:2023.11.20
※本記事は、ブレインパッドが運営する人工知能ブログ「+AI」に掲載されている記事の転載版になります。
現在、人工知能(AI)は人びとの生活や産業に革新をもたらす技術として世界中で注目されています。本ブログではこれからビジネスにAIを活用する方に向けて、ブレインパッドの入社1年目が先輩社員から学んだAIの“基礎”を連載形式でお届けします。第6回目は「人工知能(AI)を支える「機械学習」の手法」をわかりやすく解説します。
第5回「人工知能(AI)を支える「機械学習」の全体像」では、AIを支える要素技術である機械学習の仕組みをながめながら、その可能性と限界について学びました。実際に機械学習をビジネスで活用するためには、解くべき課題によって適切な機械学習の手法を選択する必要があります。
そこで連載第6回目の今回は、機械学習の各種手法の特徴と主な用途について理解を深めていきます。
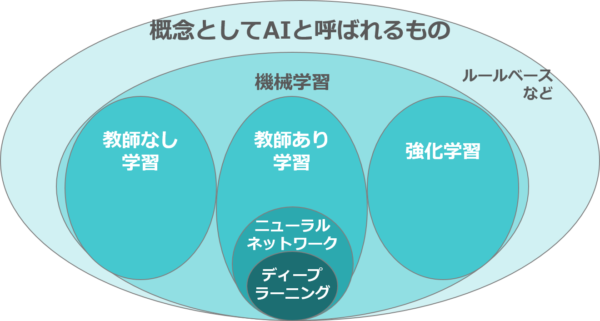
機械学習は、取り扱う問題や適応可能な対象の違いから、「教師あり学習」「教師なし学習」「強化学習」の3つの手法に大別できます。
「教師あり学習」とは、入力に対してあらかじめ正解がわかっている場合に、問題と正解をひとまとめにしたデータを学習させ、未知の状況を理解するためのパターンやルールを発見する手法です。
機械は「犬」の画像を入力しても、そこに写っているものが犬である、と人間のように判断することはできません。そこで、画像とともに「この画像に写っているのは犬である」という正解を入力します。この正解ラベル付きのデータを「教師データ」と呼びます。
「教師なし学習」とは、正解のないデータから、共通する特徴を持つグループを見つけたり、データを特徴づける情報を抽出したりする手法です。
そして「強化学習」とは、機械が自ら試行錯誤しながら、最適な戦略を学習する手法です。
各手法で利用に適した状況が異なるため、それぞれの特性を理解し、解くべき課題に応じて適切に手法を選択する必要があります。
次章からは、簡単な例を交えながら機械学習の各手法の理解を深めていきます。
正解付きのデータからルールやパターンを見出してモデルを構築し、未知のデータに対して識別や予測などの推論を行う手法が教師あり学習です。
これは既知の情報をもとに未知の情報を推論するという、人間が行っている情報処理を代替できます。そのため、ビジネスにおいて最も実用に適した手法といえます。実際、機械学習の先進的な事例の多くは、この教師あり学習によるものです。
AI研究にブレイクスルーをもたらした「ディープラーニング」も、教師あり学習の手法のひとつである「ニューラルネットワーク」の発展形です。
そのため機械学習をビジネスで活用する上では、教師あり学習の正しい理解が欠かせません。
教師あり学習で扱える問題は、推論を行う対象の種類によって「回帰」と「分類」の2つに分けられます。
推論、すなわち識別や予測を行う対象が「売上」や「来場者数」など、数値(ある値から別の値までの間に無限に値が存在する連続値)である場合「回帰」と呼びます。
回帰の代表的な手法には、2つ以上の説明変数で1つの目的変数を予測する「重回帰分析」があります。
「説明変数」とは推論を行うために用いる変数、「目的変数」とは推論を行う対象となる変数のことです。
たとえば、ある商品の売上を気温と湿度から予測する場合、重回帰分析を用いることができます。このとき、気温と湿度が説明変数、商品の売上が目的変数となります。
推論を行う対象が「男性か女性」「購入か非購入」「健康か不健康」などのようにラベル(ある値から別の値までが連続していない値をとる離散値)の場合「分類」と呼びます。
分類の代表的な手法には、目的変数が「購入か非購入」などのように「0か1のどちらかの値」で表現されるときに用いられる「ロジスティック回帰」などがあります。
正解のないデータからルールやパターンを見出す手法が、教師なし学習です。正解がない状況において、学習によって何を明らかにしているのでしょうか。その代表的な例が2つあります。
1つ目は、類似するデータのグルーピングを行う「クラスタリング」です。クラスタリングのイメージを掴むため、以下の図を用いて説明します。
ここに無作為に置かれたいくつかの図形があります。このままではどのような図形が含まれているかを読み取ることは難しいと思いますが、色や形、位置などの特徴によってまとめることで、解釈しやすくなります。
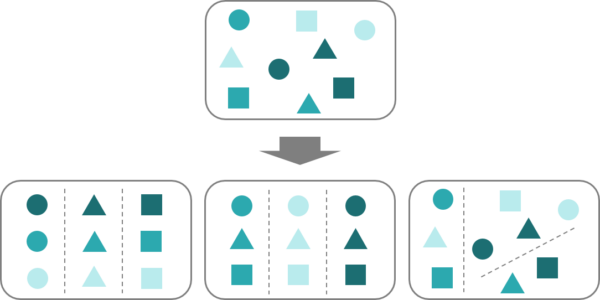
このようにクラスタリングでは、正解である情報を与えずにデータが持っている特徴に応じて、自然な分類や特徴のまとまりを抽出することを試みます。
ビジネスにおける活用シーンとしては、たとえばユーザーを興味分野でグルーピングし、それぞれの嗜好性に合ったマーケティングを行うことが可能になります。
2つ目は、データの次元(説明変数の数)を削減する「次元削減」です。
代表的な手法として、主成分分析があります。これは、多次元のデータをできるだけ情報を損なわずに低次元に情報を縮約する手法です。
たとえば、「年収・学歴・年齢・勤続年数・貯金額・負債額」という6次元のデータを縮約し、「信用度」に相当する指標を抽出してローンの与信審査に活用したり、多数のアンケート項目をいくつかのわかりやすい指標にまとめてアンケート結果を解釈するといったことが可能です。
次元削減は、より本質的なデータを抽出する以外にも、教師あり学習のモデル精度改善やデータサイズ縮小のために行う前処理などでも活用されます。
強化学習は、主にゲームやギャンブルなど、結果が出るまでに時間がかかるタスクや多数の繰り返しが必要になるタスクにおいて、機械が実際に行動しながら試行錯誤を繰り返し、最適な戦略を学習する手法です。
強化学習を理解するためには、「エージェント」「環境」「行動」「報酬」の4つの概念が重要になります。

エージェントは、「環境」において何らかの「行動」を取り、その行動に対する「報酬」を得るという処理を繰り返すことで、報酬が最大化するような戦略を学習していきます。
強化学習のイメージをつかむため、ロボットが卓球のやり方を学習していく動画をご覧ください。
はじめは相手コートにボールを返せないロボットですが、段々とコツを掴み、最終的には人間と対戦できるレベルにまでなっています。
Towards Learning Robot Table Tennis / YouTube
このように、決められたルールの中で試行錯誤しながら将来の価値を最大化することを目的とする強化学習は、囲碁やゲームなどと相性がよく、世界のトップ棋士を破った「AlphaGo(アルファ碁)」にも、強化学習が活用されています。
強化学習の技術的な説明は、ブレインパッドのブログでも詳しく紹介しています。
強化学習入門 ~これから強化学習を学びたい人のための基礎知識~
近年AI・機械学習の研究が進み、実社会への実装が加速した大きな理由の1つに「ディープラーニング」の登場があります。ここでは、ディープラーニングの基本的な仕組みについて学んでいきます。
ディープラーニングを理解するためには、まず、ニューラルネットワークについて理解する必要があります。
人間の脳はニューロンと呼ばれる多数の神経細胞で構成されており、ニューロンが複雑に結合したネットワークによって情報処理が行われているとされています。
この人間の脳神経回路を模したモデルを用いて高度な情報処理を行うのが、ニューラルネットワークです。
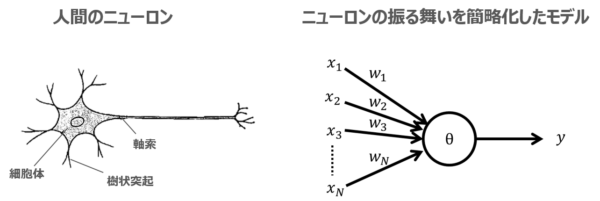
ニューラルネットワークは、ニューロンに該当する多数のユニットから構成されます。各ユニットは入力に対して、ユニット間の重みを加味した非線形な演算を行った結果を出力するという構造を持ちます。
このニューラルネットワークの層を多数重ねたものを「ディープニューラルネットワーク」と呼び、それを用いた機械学習の手法を「ディープラーニング」と呼びます。
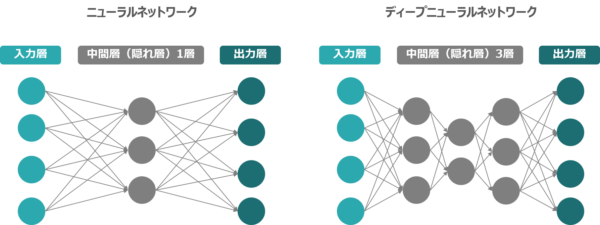
ディープラーニングの学習の主なアルゴリズムの1つに「誤差逆伝播法」(Backpropagation)があります。誤差逆伝播法とは、入力(学習データ)と出力の誤差を計算し、誤差がだんだん小さくなるように出力層側から順に各ユニットの重みを調整していく方法です。
1986年には「誤差逆伝播法」がすでに提唱されていましたが、中間層が増えて複雑なネットワークになると学習が困難になってしまいました。その原因は、重みの調整を中間層の出力層側から順に行うことにより、入力層に近い層の重みが十分に調整されなくなってしまうためでした。
この問題は長らく解決の糸口が見つけられていませんでしたが、ネットワーク構造や学習アルゴリズムの改善、演算速度の向上などによって、複雑な処理を高い精度で行うことができるようになってきました。
特定のタスクでは高い精度を誇るディープラーニングですが、取り組む課題によってはその他の機械学習の手法を選択するほうが良いこともあります。
ディープラーニングで十分な精度を出すためには、他のモデルよりも非常に多くのデータが必要です。また、大量のデータを用いて複雑な処理を行うために、処理能力が高いハードウェアも必要になります。
データが少ない場合はディープラーニング以外の手法の方が高い精度を示すこともあります。データ量や計算資源、学習時間などを考慮して、適当な機械学習の手法を選択することが重要です。
ディープラーニングは、与えられたデータを識別・予測するだけではなく、データ自体を機械が生成する「生成モデル」でも大きなブレイクスルーをもたらしました。その代表的なモデルが、「敵対的生成ネットワーク:GAN(Generative Adversarial Network)」です。
通常、教師あり学習を行うためには正解ラベル付きのデータが大量に必要となりますが、膨大なデータに人手でラベルを振るのは相当なコストがかかります。
ところが、GANを使えば学習データ(訓練データ)と似たデータを生成することができるため、正解ラベル付きのデータが少なくてもGANでデータの量を増やして学習を行えるようになることが期待できます。
FacebookのAI 研究所所長Yann LeCun氏は、GAN を「機械学習において、この10年間でもっともおもしろいアイデア(This, and the variations that are now being proposed is the most interesting idea in the last 10 years in ML, in my opinion.)」と形容するなど、機械学習の業界では大きな注目を集めています。
GANでは、Generator(生成器)とDiscriminator(識別器)という2つの学習モデルを用います。GANの発案者Ian Goodfellow氏は、この2つの関係を紙幣の偽造者と警察の関係を例にとって説明しています。
偽造者(Generator)は警察(Discriminator)を騙そうと、できるだけ本物に近い偽札を作れるようになっていきます。一方、警察も目利き能力を上げて、ほんの僅かな違いも見抜けるようになっていきます。このイタチごっこを繰り返していくうちに、結果的に本物そっくりの偽札を作ることができるのです。
GANはこれと同じ仕組みで、GeneratorとDiscriminatorが互いに学習を進めていき、最終的にGeneratorは学習データと同じようなデータを生成することを目指します。
以下の動画では、実在するセレブの画像を訓練データとして学習させ、GANが徐々に高解像度(1024×1024)の「セレブっぽい画像」を自動生成していく様子が分かります。
Progressive Growing of GANs for Improved Quality, Stability, and Variation / YouTube
また、GANを応用した活用事例としては、昨年Berkeley AI Research laboratoryとUC Berkeleyが公開した「CycleGAN」があります。これを用いると、下の画像のように、「馬とシマウマ」「写真と有名画家の絵画」「夏と冬」などを相互に変換することができます。

このように大量のデータが必要な教師あり学習において、その問題を回避する可能性のあるGANですが、「その可能性を最大限に引き出すためにはさらなる研究が必要だ」とGoodfellow氏は言います。
現在は、機械が比較的理解しやすい対象のデータを生成することはできますが、複雑なデータでは本物と呼べるデータを生成できないことも多くあります。今後研究が進むことにより、複雑なデータの生成なども可能になり、ビジネスへの利用可能性も拡大してくることが期待されています。
ここまでみてきたように、機械学習は様々な手法がありますが、それぞれ利用に適した対象や目的は異なります。機械学習をビジネスに活用するためには、解くべき課題を見極め、その適切な手法を選択することが重要です。
***
連載第6回目となる今回は、AIを支える要素技術である機械学習の各手法の特徴についてみていきました。次回は、AIの市場構造についてふれながら、実際にAIを活用したプロジェクトを推進するための方法について学んでいきます。













